"Inline IMDB ratings" script
The "Inline IMDB ratings" script finds any links to IMDB, then pulls the rating information for the corresponding movie and displays it next to the link, such as [8.4/10 rating] in this screenshot:
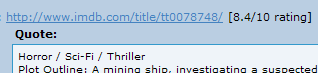
As usual, you need to use Firefox with the Greasemonkey extension to make use of this script.
API where art thou?
The script functions by scraping the HTML served by IMDB, since that site does not offer an API yet. An API would not only make this kind of mashup more maintainable, it would be a more efficient use of resources.The question is does it make sense for IMDB to signup for a bunch of additional load by opening up APIs for a basic data service?
Silos and unique identifiers:
More generally, this script points out one major limitation with the data on the web today: the lack of unique identifiers. Unlike books, which can be tracked across silos by ISBN number, or real estate sites which use MLS numbers (Multiple Listing Service Number), each site uses their own identifier to identify movies.With a unique identifier for movies and TV shows, you could build some integrations between review sites, recommendation services, showtime listings and rental services, across multiple devices (PC, media players, PVRs, cellphone).
IMDB links seem like a good candidate for this purpose, but sites like Yahoo Movies or Rotten Tomatoes probably see this as a competitive threat. I suppose that a more distributed design would have the movie companies assign unique urls to identify each movie they release, following the OpenID model.
Unfortunately, I do not see either happening in the near future. Different movie sites will remain mostly isolated in the meanwhile...
______________________________________There is an IMDB WebService you could use, it's at http://www.trynt.com/trynt-movie-imdb-api - not offical but it works.
Posted by: Franz (August 30, 2007 07:11 AM) ______________________________________I don't think that IMDB opening up some minor API would at all increase their load. If someone wants to parse their pages for data, they'll do it anyways. Would an API invite more usage? Well when you get a 10,000 byte page for 3 bytes of information, that's quite a gap to fill. Not to mention all the DB queries saved.
Posted by: Tony (September 4, 2007 10:29 PM) ______________________________________Thanks for very interesting article. btw. I really enjoyed reading all of your posts. It’s interesting to read ideas, and observations from someone else’s point of view… makes you think more. So please keep up the great work. Greetings.
Posted by: Sportlernahrung (September 12, 2007 03:59 AM) ______________________________________Thx for the great stuff. ill download he script
Posted by: thomas (September 13, 2007 09:27 PM)