Git Internals
I started to use Git more regularly and was curious about its design. Pro Git is an excellent and free book on using and understanding Git. I’ll share some minimalist notes I took on Git’s internal design. The design is simple and elegant. It’s been very enjoyable to learn about.
Object model
The Git object model has three types: blobs (for files), trees (for folder) and commits. Objects are immutable (they are added but not changed) and every object is identified by its unique SHA-1 hash.
A blob is just the contents of a file. By default, every new version of a file gets a new blob, which is a snapshot of the file (not a delta like many other versioning systems).
A tree is a list of references to blobs and trees.
A commit is a reference to a tree, a reference to parent commit(s) and some decoration (message, author).
Then there are branches and tags, which are typically just references to commits.
This illustration (borrowed from Pro Git) shows branches, commits, trees and blobs and their relationships:
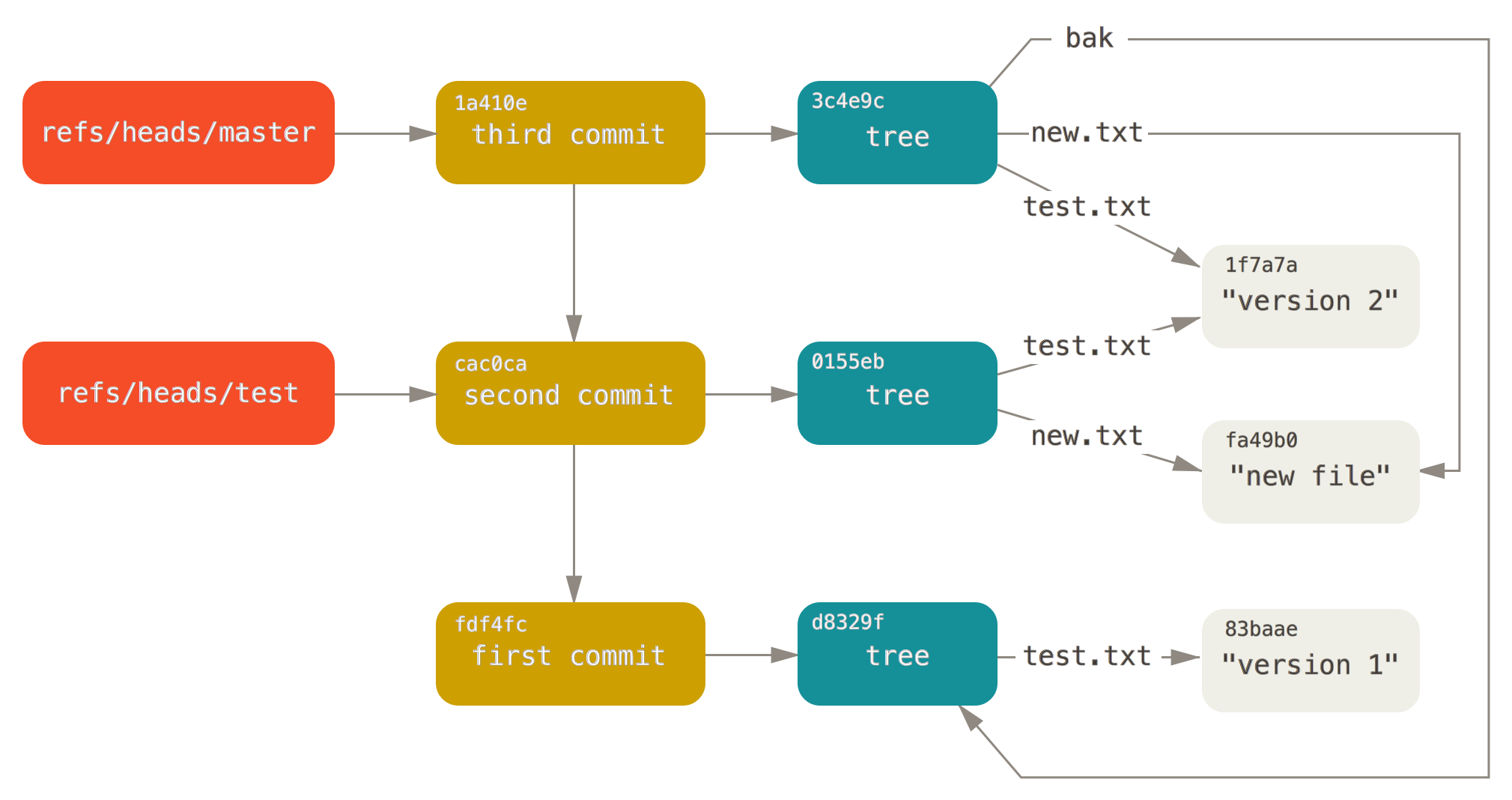
High-level Git commands (init, add, commit) are the most common way of manipulating the object model (and its underlying stored representation), but Git also offers a number of low-level commands (for instance to create a blob object).
Storage format
Let’s move on to the physical storage of those objects. All the repository data is stored in the .git folder, which has the following structure:
objects/
refs/
HEAD
config
description
hooks/
info/
We’ll cover objects, refs and HEAD.
Objects folder
The .git/objects folder looks like this:
<SHA-1 named files>
pack file and index file
All objects are store in this folder, using their SHA-1 identifier as filename (the first two characters of the identifier are used as sub-folder). The objects can optionally be packed, in which case they get moved into a pack file, which comes with an index file.
As we’ve seen, each type of object holds different kind of information:
- blob (contents of a file)
- tree (list of filenames, each with a SHA-1 reference and an object type, which can be normal, executable, symbolic link or directory)
- commit (reference to toplevel tree, author information and commit message)
Each object type has a specific serialization to file. For instance blob objects are serialized as “blob <space> <content length> \0 <content> <linefeed>” which is then compressed with zlib.
Pack file
As you commit multiple versions of a file, the objects folder grows and contains a lot of duplication. A git command allows to pack the objects. This creates an index file and a pack data file.
The index is a list of SHA-1 object identifiers that got packed, and for each, some information for finding the object in the pack data file.
The data can be stored in different ways in the data file (either a snapshot or a delta), so depending on the case the index row will contain different information:
- Simple or snapshot index entries have an identifier, object type, object size, and start/end offsets for finding the blob in the pack data file.
- Delta index entries have an identifier, object type, the SHA-1 identifier of the baseline object, and start/end offsets for finding the delta blob in the pack data file.
When git packs the objects, it decides which objects to keep as snapshot and which to keep as delta.
references folder
The .git/refs folder looks like this:
refs/heads
refs/tags
refs/remotes
All the objects we have stored so far can only be accessed if you know their identifier. The branches and tags are ways to keep a handle on a few of those identifiers, by giving them a friendlier name and allowing to enumerate them.
heads contains files named after branches. Each holds the SHA-1 reference of a commit object.
tags contains files named after tags. Each contains the SHA-1 reference of a commit object (for simple tags, without annotations).
Finally, the file .git/HEAD contains the pathname to the head file (for instance refs/heads/master) which you currently have checked out.