Git Internals - branches and remotes
My previous article on Git Internals described the object model for a single repository. But how do distributed repositories work together?
As I’ll try to explain, immutability is the foremost key.
DAG of commits
The core design of Git revolves around building a graph of commits where each commit points to its parent(s) commit(s) and to a tree of objects (representing files and folders). Commits and tree objects are immutable; they can be added, but never modified.
This immutability (and the fact that all those objects have globally unique content-based identifiers) make it safe for people to party on this graph across the world.
Each contributor is just adding new commits to the graph, each with a new object tree. The new commits can reference existing commits and the new object trees can reference existing tree objects. All those new objects could then be safely shared to others without conflicts. At the same time, no single Git instance has the complete view of the graph that is getting built.
References
Not everything in Git is immutable though. Branch references, which are also simply called branches, are updateable references to commits.
The key to avoiding distributed conflicts is clear ownership: a repository can only modify branches it owns, and receive updates for other branches from their owners.
Branch names are namespaced, so you can tell which ones each remote repository owns and which ones your local instance owns. If your repository is linked to “remote1” and “remote2”, their branches will be named “remote1/blah” and “remote2/foo”, while your local branches will simply be named “bar”.
Fetch, merge, rebase, push and pull
We’ll now look at some operations and how they affect the commit graph and the branch references.
Fetch get updates from a remote repository. You will get updated branch references and all the objects necessary to complete their history.
This does not update your own repository’s branches and therefore is conflict-free.
On the other hand, merge and rebase will update one of your repository’s own branches. Both merge and rebase are designed to handle divergence between two* branches. Those could be two* local branches, but I’ll explain the case where your local branch added commits and its corresponding remote branch added other commits.
Merge will create a new commit with two* parents: the commit referenced by the remote branch and the one referenced by your local branch. It is generated by considering all changes since their common commit ancestor, and may require manual intervention to resolve conflicts. Your local branch is then updated to reference this commit after it is created.
The degenerate case where the your branch had no changes is simpler. Your local branch was the common ancestor and will be updated to match the remote branch, without need to make a new commit. It is called fast-forward.
A pull operation simply combines a fetch and a merge.
Rebase will create a chain of new commits which descend from the commit referenced by the remote branch and then update your branch to reference the last commit in that new chain.
Those new commits replay the changes you had in your local branch (since the common ancestor commit). The chain that is generated could be interactively tweaked during rebase, for instance to combine or split the original commits in some way.
Both merge and rebase will only update one of the branches (the working branch) and leave the other(s) unchanged.
Push sends some new commits of yours to the remote repository and ask it to update one of its own branch references. The normal case (no forcing) is restricted to a fast-forward.
Example
Let’s look at an example of divergence, merging and rebasing, using illustrations borrowed from Pro Git.
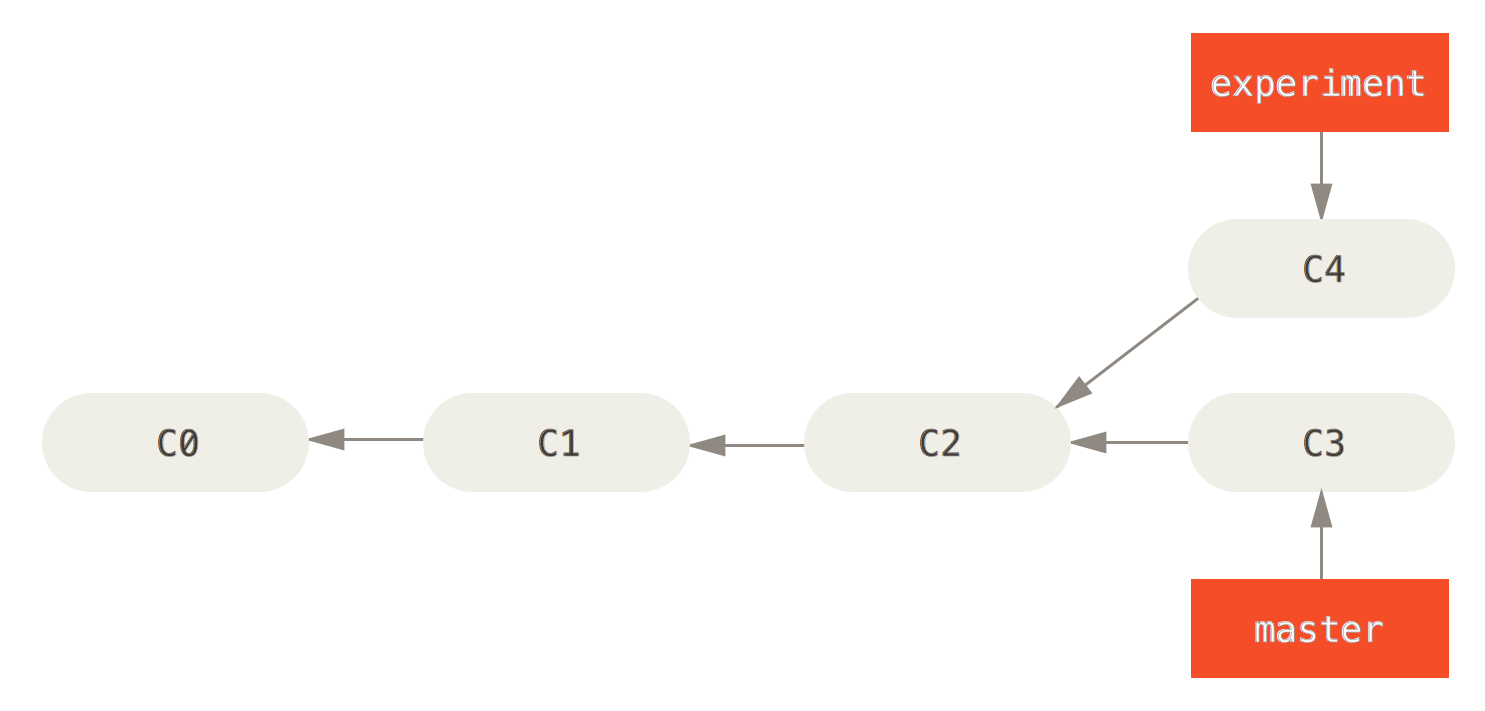
The first figure shows two local branches (master and experiment) that diverged by adding one commit each (C3 and C4).
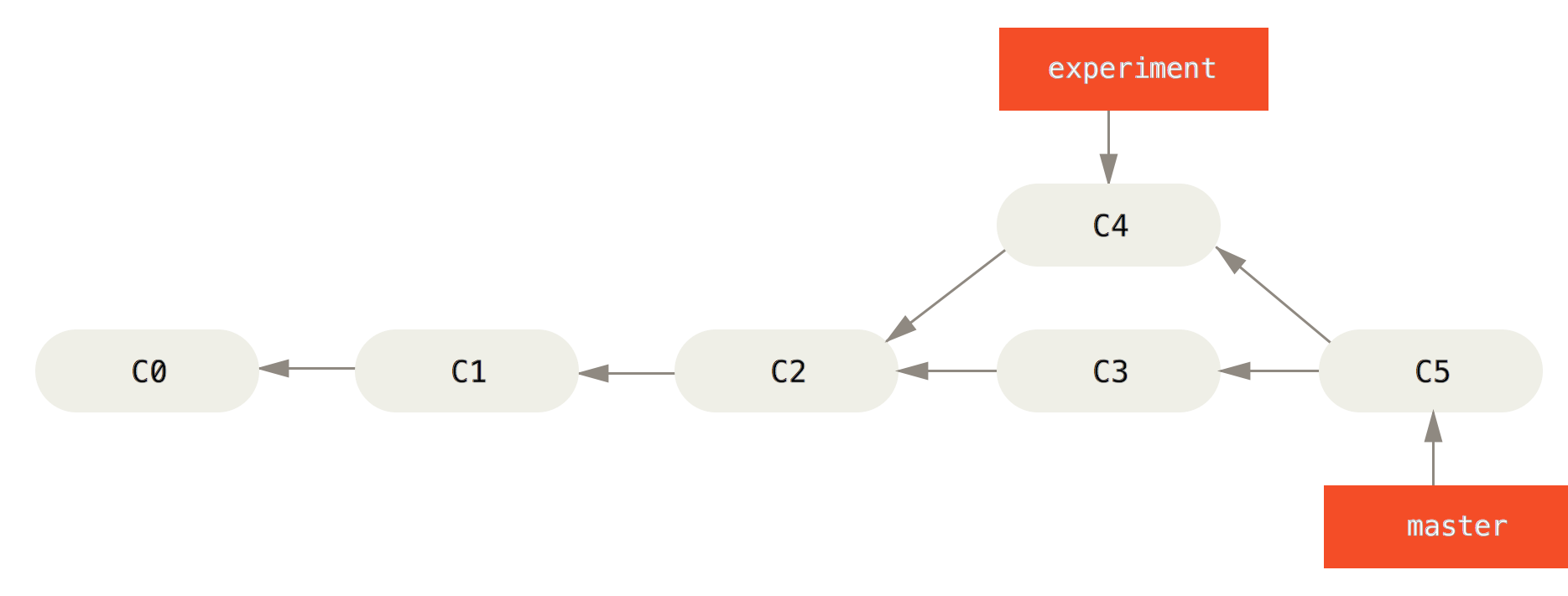
Merging is one way to handle this divergence. It adds a new merge commit (C5) which has two parents and updates one of the branch references (master in this instance).
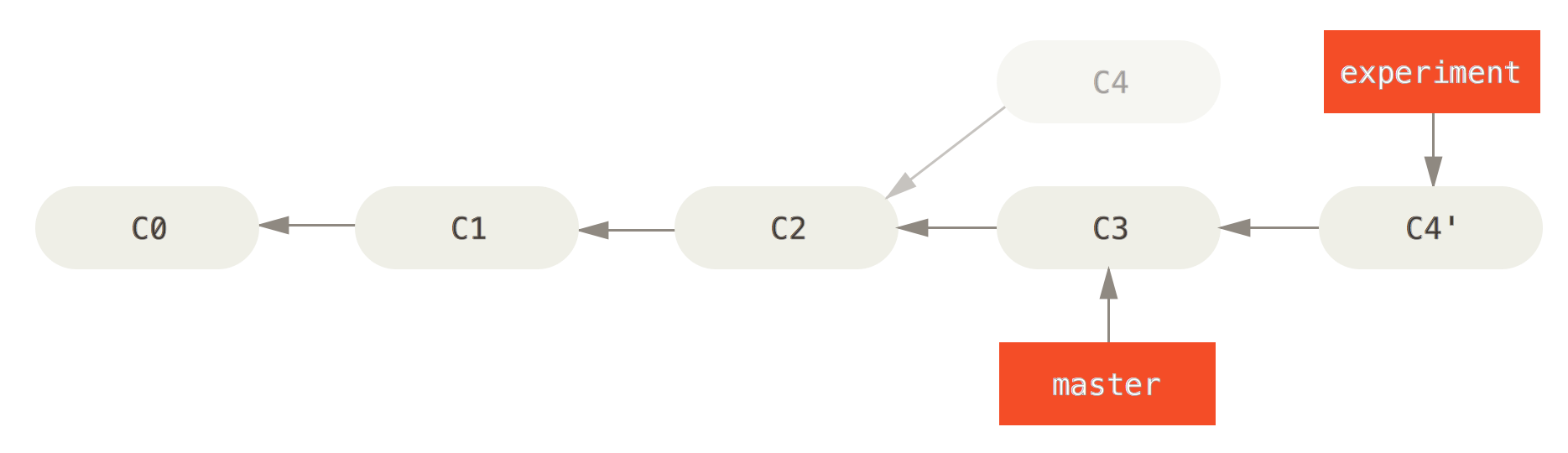
Another way to handle this same situation is to use rebase. Instead of creating a merge commit with two parents, it adds a new chain of commits to one side. Those new commits (C4') replay the changes on the other side of the divergence (C4) since the common ancestor (C2). Then it updates the other branch reference (experiment).
Some commits may be left hanging with no reference, such as C4 here.
After this rebase, if we try to update the master branch with a merge of the experiment branch, this will be a fast-forward merge. It simply updates the master reference and does not require creating any new commit.
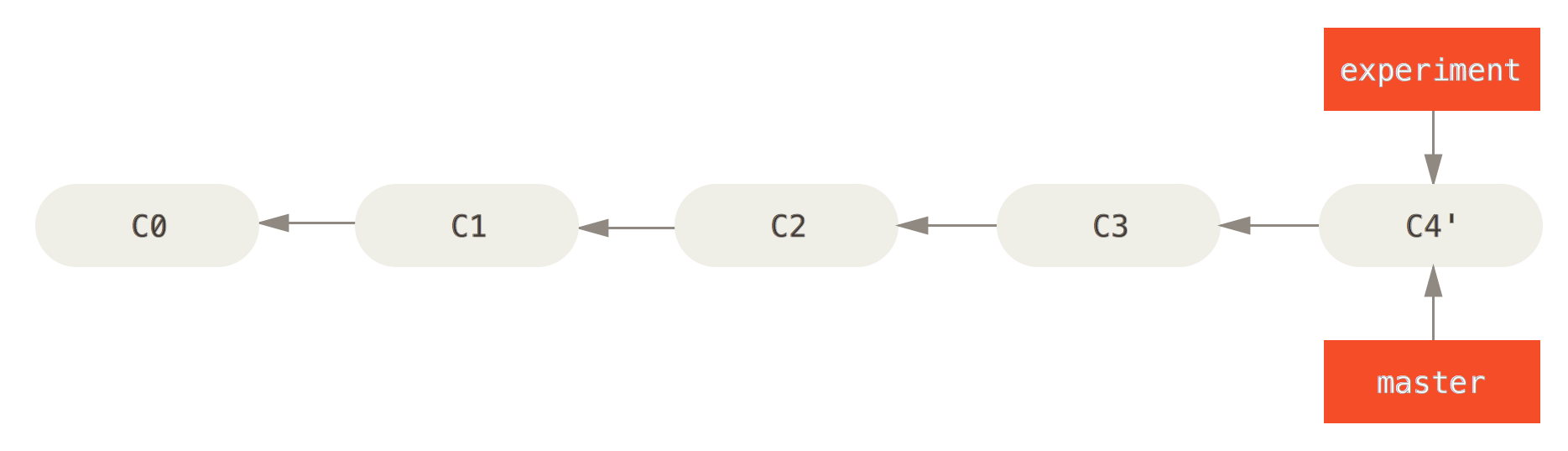
This example used two local branch names, but the operations work exactly the same with one remote branch, which is read-only to you, and one local branch, which will be updated.
Summary
To recap, there are a few keys that illuminate Git’s design:
- Commits and object trees are immutable.
- Commits and objects have globally unique identifiers.
- Branches are mutable references to commits, but are namespaced by repository and have clear ownership rules.
Although a couple of people have identified immutability in particular to be a key in Git’s design (Scott Chacon in his excellent Getting Git talk or Philip Nilsson), I’m surprised that this is not more commonly emphasized. With those keys, its design becomes much easier to understand in its simplicity and elegance.
PS: The GitHub team put together a kind of git simulation/visualization tool (more details). Type git commands and see the commit tree get updated. (via).
Along those lines, there is also an interactive git tutorial which not only has a visualization but is structured into mini-games of different levels.